Kapat
Popüler Videolar
Moods
Türler
English
Türkçe
Popüler Videolar
Moods
Türler
Turkish
English
Türkçe
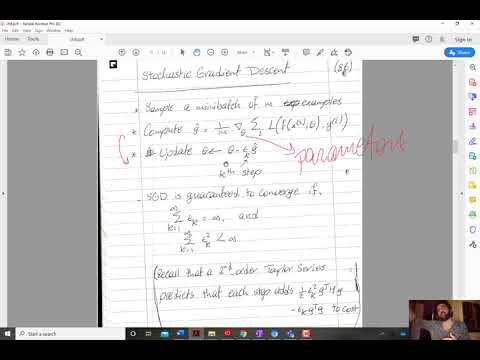
Lecture 6.1 — Overview of mini batch gradient descent [Neural Networks for Machine Learning]
8:23
|
Yükleniyor...
Download
Hızlı erişim için Tubidy'yi favorilerinize ekleyin.
Lütfen bekleyiniz...
Type
Size
İlgili Videolar
L1W4 Part2 Batch, Mini-Batch and SGD
15:38
|
Stochastic and Mini-batch Gradient Descent | Sinhala
16:35
|
Gradient Descent Algorithm | Deep Learning | Sinhala
16:19
|
Introduction to Deep Learning - Module 3 - Video 55: Introduction to Stochastic Gradient Descent
6:10
|
Introduction to Deep Learning - Module 3 - Video 56: SGD Learning Rate
7:28
|
PERCEPTRON | STOCHASTIC GRADIENT DESCENT | BACK PROPAGATION | DEEP LEARNING - PART 3 🖥️🧠
11:49
|
CS 480/680 - Lecture 11b - Deep Networks
47:16
|
CS 152 NN—2: Intro to ML— Data+Answers=Rules
7:12
|
67 AdaGrad (Adaptive Gradient) Optimization - Minimize the Cost
10:18
|
Introduction to Deep Learning - Module 3 - Video 57: SGD Convergence
8:47
|
Optimization in Machine Learning: Lecture 6.2 (SGD for Deep Learning)
1:22:55
|
Which one to use in SGD, BGD and Mini Batch GD | AI SOCIETY | Sameer Nigam
4:48
|
Batch Normalization ගැන සිංහලෙන් | Deep Learning
22:11
|
Introduction to Deep Learning - Module 3 - Video 64: Adaptive Learning Rate
10:34
|
Caltech CS 155 (Winter 2019) Lecture 7
1:13:13
|
Stochastic Gradient Descent in Machine Learning | Machine Learning with Python Tutorial | Session-19
44:12
|
Lecture 11 Statistical and Algorithmic Foundations of Deep Learning
1:18:52
|
Introduction to Deep Learning - Module 3 - Video 53: Local Minima and Saddle Points
10:18
|
Stochastic Gradient Descent with Momentum | Deep Learning | Sinhala
10:22
|
Second order optimizations for scalable training of DNNs by Dr. Andrew Lumsdaine
58:42
|
Copyright. All rights reserved © 2025
Rosebank, Johannesburg, South Africa
Favorilere Ekle
OK
![Lecture 6.1 — Overview of mini batch gradient descent [Neural Networks for Machine Learning]](https://i.ytimg.com/vi/4BZBog1Zx6c/hqdefault.jpg)